AI Agent Quant Research: A Reality Check
Academic AI Agent papers abound: LLM auto factor mining, evolutionary strategies, multi-agent collaboration... We replicated the experiments. Here's what we found.
Using QuantaAlpha, CSI300 market, 2022 out-of-sample backtest. Three groups: Blue line Alpha158 baseline (20 factors, no mining) | Orange line QuantaAlpha without evolution | Green line QuantaAlpha with evolution (Dir=2, Rounds=3)
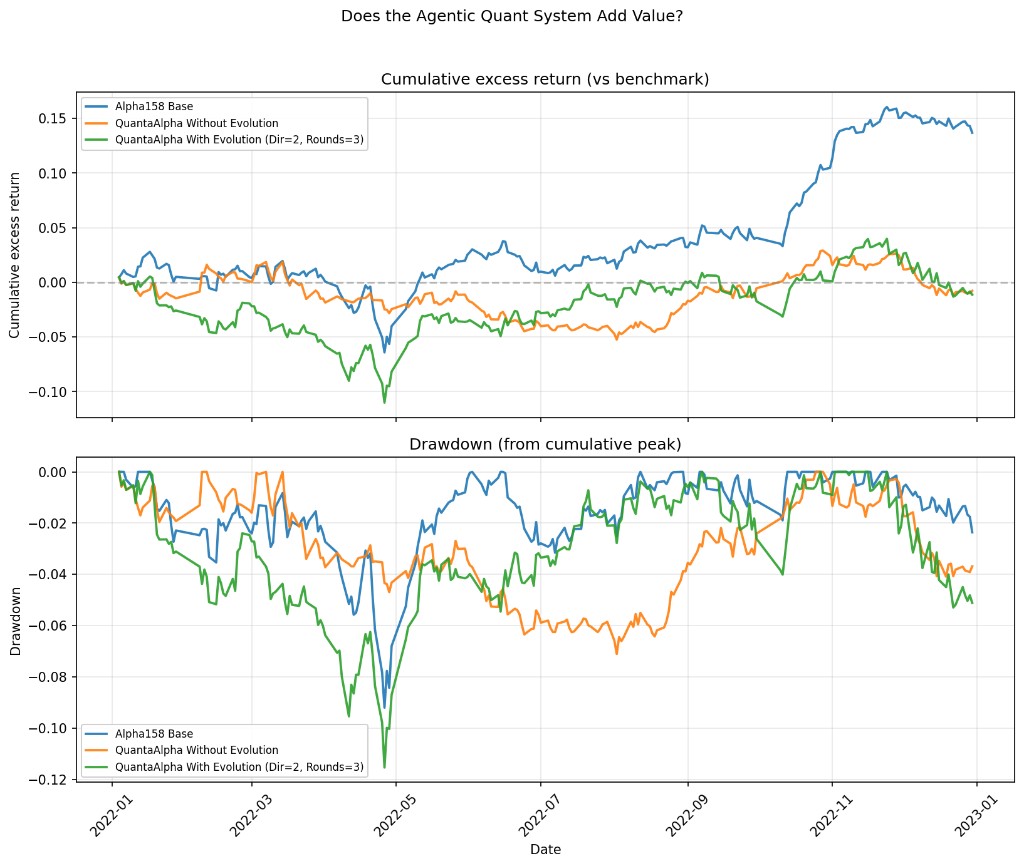
From batch_summary.json + cumulative excess CSVs (2022-01-04 to 2022-12-30, vs CSI300 benchmark):
| Experiment | Cum. excess return | Max drawdown | Rank IC |
|---|---|---|---|
| alpha158_20 (baseline, 20 factors, no mining) | +13.69% | -9.20% | 0.0325 |
| combined_fresh_exp2 (QuantaAlpha seed, no evolution) | -0.78% | -7.11% | — |
| combined_fresh_exp4 (QuantaAlpha with evolution, Dir=2 Rounds=3) | -1.13% | -11.54% | — |
In other words: spending substantial compute on LLM mining and evolution did not beat 20 classic price-volume factors in this experiment.
We're not dismissing AI Agents—there's real potential. But many papers have experimental design that doesn't hold up under scrutiny: cherry-picked periods, weak baselines, no replication after publication—this kind of 'serious nonsense' is common in top venues.
In quant, we fear nothing more than self-delusion. A strategy that makes money is what matters. Can Agents help? Perhaps. But show us real backtest results first—don't hide behind fancy frameworks.